During install IBM Installation Manager, got this error "jvm terminated exit code 13", checked the jvm version,it's right, then grant all sub-folder with execution permission, then it work!
At first I just did "chmod +x *" for current folder, it should be executed as " chmod -R +x *"
Monday, 16 December 2013
Wednesday, 4 December 2013
Why is the CPU's behavior different with same test suite?
I ran a same test suite on two different platforms:
1) Drive server : redhat5.4, under test server : aix6.1
2) Driver server: redhat6.0, under test server: win2k8
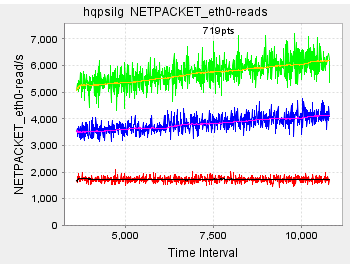
There is a CPU usage increasing trend on #1 drive server as the chart: https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhRC1SxPskw7oENwotLAxbfza22irk26H2y06wjyIu_lOT5Bzqxey9GIabwoDCU3WMENUXRT5F1YAtM1XvT6Wygki-ehkgaJH5GLd6ZZ2U0MF17EArlE8yzdoANUL9tW4HwsxjNrEkZNU04/s320/cpuIncreasing.PNG, but it is really stable on #2 drive server as this chart .https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjhflIFcJ2TV7sRGTJAOICbwRpS9tWXvfQhb85Qe43RLVOA_rFafbLi_DFlWEZIfkIcXZWiWoEbePbm2cgg4Ezv3BIdm2G5lC91mHqwqrDFRSo-gY2HtNfG9htl3RA-v5k3q8epAdelngsm/s320/cpuNormal.PNG I checked the network transfer rate is also increasing on #1 drive server as the chart https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg65JEwv-Z6Y-OrxTILGwajh3uirIVrA2QAnQu8nEOC2jnkL-nsshKR-cTA-y8oCahm78Q0ee1t5Xk1lFBenHVxtKzRVkU8Gi-zXjB0_Gf0eqEaQ5eGcIGkzUZmioWbBge4C9vof09oDEgf/s320/eth0_netpacket_read.PNG so I think it maybe the reason which caused CPU increasing, but I am curious why it didn't appear on #2 drive server?
1) Drive server : redhat5.4, under test server : aix6.1
2) Driver server: redhat6.0, under test server: win2k8
There is a CPU usage increasing trend on #1 drive server as the chart: https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhRC1SxPskw7oENwotLAxbfza22irk26H2y06wjyIu_lOT5Bzqxey9GIabwoDCU3WMENUXRT5F1YAtM1XvT6Wygki-ehkgaJH5GLd6ZZ2U0MF17EArlE8yzdoANUL9tW4HwsxjNrEkZNU04/s320/cpuIncreasing.PNG, but it is really stable on #2 drive server as this chart .https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjhflIFcJ2TV7sRGTJAOICbwRpS9tWXvfQhb85Qe43RLVOA_rFafbLi_DFlWEZIfkIcXZWiWoEbePbm2cgg4Ezv3BIdm2G5lC91mHqwqrDFRSo-gY2HtNfG9htl3RA-v5k3q8epAdelngsm/s320/cpuNormal.PNG I checked the network transfer rate is also increasing on #1 drive server as the chart https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg65JEwv-Z6Y-OrxTILGwajh3uirIVrA2QAnQu8nEOC2jnkL-nsshKR-cTA-y8oCahm78Q0ee1t5Xk1lFBenHVxtKzRVkU8Gi-zXjB0_Gf0eqEaQ5eGcIGkzUZmioWbBge4C9vof09oDEgf/s320/eth0_netpacket_read.PNG so I think it maybe the reason which caused CPU increasing, but I am curious why it didn't appear on #2 drive server?
Thursday, 21 November 2013
What's factors will cause weird cpu usage?
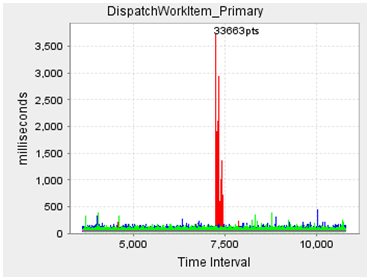
- We have a performance test tool we owned, which written by java. Recently I run three tests with 200/400/600 threads, and found the system CPU usage as the chart: (red-200,blue-600,green-400). I can't explain what factors will cause this kind of result, any ideas?

The GC activities are normal:
CPU Usage increasing on redhat5.4 platform


Monday, 6 May 2013
Can we say it is memory leak?
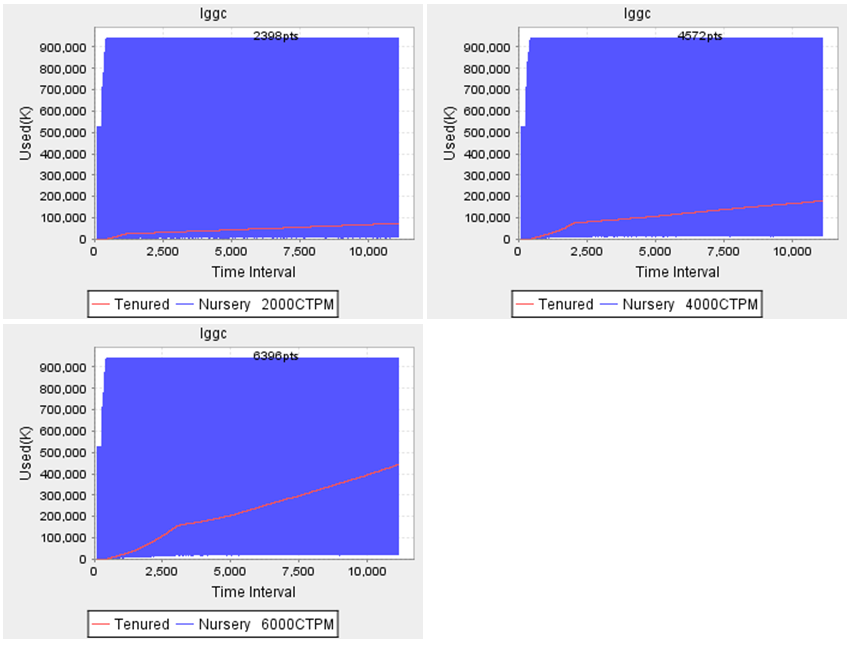
This is a 3 hours test, got these charts from GC log.


Andreas Kral ? I would rather go for the heap used then the GC pauses..
Plot the gc graph and make a line at the beginning low and a line at the right end low after the last full GC. Measure the gap in MB or GB,then get a tool like yourkit and find the class that fits closest to the gap.
Peter Booth ? Maybe. It depends on your context. A memory leak in Java is a situation where your code is retaining references to objects that are no longer needed, and so the garbage collector doesn't collect those objects.
What are the JVM startup arguments?
Your GC usage graph looks similar to what we see when an app is started with an Xms value lower than the Xmx, and so begins with a small heap size, and periodically resizes the heap (increases it.) Can you produce a chart that clearly marks the Full GC events?
If you continue to drive realistic traffic at your app does the upward trend in heap usage continue, or does it stabilize? Are the JVM settings used here similar to real world production settings for this app? Is the traffic similar to real world traffic?
Also, the other chart shows GC pauses of over 1 second. For a batch oriented system this might be unimportant, whereas for an internet based web app this is probably unacceptable. Is this an issue in your situation?
I ask these questions because this isn't a black and white question- you can have an app that is memory hungry and has a GC profile identical to your chart, but which quickly plateaus. If your heap is sized too low then this would provoke an OutOfMemoryError and fail, but with the right sized heap would perform OK.
Oleg Gusak ? The other thing to know is what garbage collector your app uses. For parallel collector plotting old gen size after Full GC over time would tell you if size of live object in old gen is growing - and that would indicate a memory leak.
Reddy Sravan ? There are two issues in your case. The memory is not enough for the amount of load u are running, this will be identified from GC pauses graph, the pause time increasing along the test
This memory unavailability will impact several things, Heap, logging, CPU etc
I also see the used memory graph, bottom end is increasing i,e GC is retaining objects inside memory which could be due to heap being low or a memory leak
There is two ways to analyze from here
1) take stderr logs and look for GC application failures and how much free nursery vs tenured (if not enough try increasing heap size and run test again)
2) take heap dumps and look for any objects staying in memory and growing over time, talk to developer to resolve the issue
Satyanarayana Murty Pindiproli ? Agree with peter and Sravan. Though analyzing heap dumps will take a long time to identify the culprit objects if there really is a leak. It could be caching as well in application which is causing these objects to be reatined. So its application specific. I would suggest taking heap histograms after specific time intervals and compare those to see which objects are increasing. Use the Heap dump to look for the reference graphs and your developers should be able to fix it. Also take a look at Perm Size for the Applications. If that is getting filled up quickly; that results in collections too. Proper resizing for perm size will help. If the GCs are minor collections then you shouldnt have a problem with memory leak , but if they are full collections on tenured then yes , you are promoting and need to address that.
Peter Booth ? The easiest way to detect the cause of a memory leak is with the Eclipse Memory Analyzer toolkit. Run your app with one of XX:+HeapDumpOnOutOfMemoryError or
-XX:+HeapDumpOnCtrlBreak and trigger a heap dump, then open the hprof file with MAT and you will be able to see the cause of heap growth.
Satyanarayana Murty Pindiproli ? I think it may not be not easy to trigger so much of traffic on the development environment. Probably using the same switches on the test evnvironment would help easily identify. App Memory requirements seem to low anyways, so he can run this in dev environment ..
Sun:
Ran a longer test ~15hours



Satyanarayana Murty Pindiproli ? I think the Charts can be explained ; but only you can confirm. The use of 2GB during the initial 6 hours mean that there are garbage objects are already in the Tenured Generation. Probably Weblogic or ap startup creating all these objects. After around 6 hours, further promotion or the nature of the VM Switches did cause a Full GC. The drop in Memory Usage for Tenured is significant which shows you had a lot of grbage objects in the Tenured in the first place. If you look at the heap stats for the remaining time duration it shows somewhere in the 750 Meg - 1Gig range which is what your application typically needs. I think triggering a Full GC on the VM before the Test would be a good idea. The drop in rate i believe is due to the Full GC ; which again picks up as soon the GC is completed. If you look at the Promotions pattern in the Log files and Map it , i am sure it will line up with a spike near the time of Full GC. I do not think you have a memory leak[ Tenured Generation doesnt go up after GC ] , a memory leak would show an increasing Tenured Generation as the Objects keep piling up.
Monday, 29 April 2013
Performance Troubleshooting Process
| What | Get the whole picture of system , get a direction to anayze base on experience | |||
| What's the issue? | What's the business? Which product components be used? How much the workload? | |||
| Reproduciable or not? | ||||
| Reproduciable? | Get the steps of reproduce | |||
| Can't reproduce | Keep watching and collect required loggs | |||
| Suggestion: monitor method or tuning ,try to find the regular pattern | ||||
| Environment Information? | ||||
| Component structure | platform/HA/Cluster | |||
| Vendor & Versions | Any known issue of other products | |||
| Bussiness data model | Data distribution | |||
| External services | Any backend service : webservice | |||
| Contact information | Email&Phone | |||
| Follow up Space | 1. Easy To follow next actions 2. Archive history work | 1. new Email thread 2. new one forum thread to discussion | 1.Notes 2. Lotus connection forum of community | |
| Why | To know current action ,and know what's the next base on different result by tools | |||
| Reproduce issue in local or product base on steps from customer | ||||
| In Local | Cost consideration (new or reuse), simulate business and data model | |||
| In Customer | 1. Give guide to reproduce and collect required information 2. Get access information (host/user/pwd) , do backup firstly | |||
| Issue Pattern | ||||
| Always/Sometimes | 1. Always: resource shortage, need to monitor system resource usage. 2. Sometime: workload(hardware resource shortage or poor design) or time range(business or backend tasks). | |||
| Single User/Multiple User | 1. Single : profile every tier cost to locate bottleneck 2. Multiple : check appserver/db pool usage (thread/connection…) | |||
| High Resource usage | ||||
| High CPU | 1. Using OS tools to monitor which process cost CPU 2. What's the incomming requests 3. Frequency GC | 1.nmon 2. GCMV 3.perfmon | ||
| Crash | Which process cause | vmstat iostat | ||
| High Response Time or low throughput | ||||
| Functions/operations | To confirm the functions pattern 1.one. Find which one function slow, to know the business logic or backend service. 2. Some functions, they are simillar or not (retrieve / create ….) 3 all functions , to monitor system resource | |||
| Isolate the logic tiers | 1. Custom API testing log time to confirm the issue of product or custom application 2. Using system performance tool to monitor all system resource usage to confirm which tier is bad 3. Check log to find any time | 1.qatool 2.nmon 3.perfmon/ | ||
| Isolate the function module | 1. Profiling tool by single user. 2. Check trace log, apply for test env with single user. | 1.Jprofiler 2.WAS PMI 3.WAS Performance tuning toolkit | ||
| Goals | ||||
| customer | Discuss with custom to confirm a goal base on business | |||
| common | Set a common goal base on industry standard | |||
| How | To give different solution base on skills and resources | |||
| CPU | ||||
| High | 1. add CPU | |||
| Low | Less network roundtrip | |||
| Memory | ||||
| wrap | 1. increase memory 2. increase heap size | |||
| Disk | ||||
| Busy | 1. RAID 2. less write logic | iostat/perfmon | ||
| Network | ||||
| App server | ||||
| GC | 1. GC policy 2. Heap Size | |||
| Cache | 1. increase cache size | |||
| Pool limit | 1. increase pool size : thread pool/ data source | |||
| DB | Snapshot SQL Explain | |||
| Buffer pool | ||||
| Poor Index | ||||
| Bad Design ,need a workaround | ||||
| Bad index | ||||
| Load too much at one page | ||||
| Summarize | Growth | |||
| Personal | Skill Improvement | 1. Technical skill ,which knowledge is new ,to learn it 2. Troubleshooting skill ,experience improvement | ||
| Customer | Best practise for other customers | 1.To design solution for other customers or resolve same problem 2. Base current customer env ,give some suggestion to system stable. | ||
| Product | Design suggestion | 1.Analyze the reason of the issue,any possible to redesign the product? 2. Analyze why it doesn't be test? 3. Give a suggestion to improve product monitor |
Means: a. system resource limitation. b. bad logic.
- Always there (Means some resource is not enough)
- Single User? (To locate which tier consume the most time. Need profiling tool to figure out.)
- AppServer profiling tool
- JVM profiling too
- Trace log
- Application debug log
- Multiple Users? To locate the bottleneck
- AppServer
- Thread pool
- Data source
- Cache
- Database
- Agents limitation
- Locks
- Buffer pool limitation
- AppServer
- System resource limitation
- High CPU
- Memory
- Disk I/O
- Network
- JVM(Optional)
- Application Performance Data (to check application logic)
- Single User? (To locate which tier consume the most time. Need profiling tool to figure out.)
- Sometimes
- Check what's functional work doing at that time
- Batch operation
- Backup operation
- Migration operation
- Cache refresh
- Check any outside factors effection
- Check what's functional work doing at that time
- Percific functions (Need to know the application logic and relative DB operations)
- Authentication
- Create
- Update
- Delete
- Search
- Retrieve
How to see percentile?


Peter Booth ? I'm assuming that we're discussing the response times of real production systems though the following is also applicable to load test results.
I routinely trac both median and 90% values, and on some occasions also look at the 10% percentile. Response times aren't normally distributed, so mean and standard deviation can be quite misleading.
The median is a useful measure for "typical experience" and is perhaps better understood than 90th percentile for most audiences. For many purposes the 90% is a "better" metric, though less familiar, and here's why:
Imagine we are tracking the response time of a web service over time, and we deploy some new code, how can we see if the new code impacts performance? The values that we measure will vary, and part of that variation is measurement error. If our change did cause a consistent change to response times, the size of the change will tend to be larger at the 90% percentile than the median, so we can distinguish it quicker.
The 10% percentile can be a useful measure of the best case response time, and, depending on workloads, the actual service time of the service.
All three metrics are useful and they are often driven by different factors- its useful to view scatter plots of actual data points which can highlight things like bimodal response times, periodicities, and absolute shifts in response times.
Manzoor Mohammed ? I normally look at a number of measures, including average, 90 percentile, standard deviation especially when looking at test results or a system I'm not familiar with. I think looking at a single metric only tells you part of the story while looking at a range of measures will give you a better feel of the distribution. If your familiar with a system you could get away at looking at averages and only look at the other metrics when you see an unusual deviation from the typical average response times.
Michael Brauner ? It is nice to know that people vary in what they look at with response times but what about other measures from the application that can and do contribute to the response times that you see. How about the backends that you are dependent upon or the connections pools for starters... :-)
Weifeng Tang ? I am confused here about your "big spikes in our test, use 90% percentile".
If 90% is meaningful, it means the spike affect less than 10% for your result. Thus you can eliminate the spike by ignore the 10%.
However, if the spike renders Median Response Time unmeaning, the number of spike may be much larger than 10%. Otherwise, since the Median the data on the 50% position, even the whole 10% is on one direction, the Median might be at 60% position(Actually, 55% or 45% if we think all these data are abnormal). In a real production environment, I would not expect a 50% --> 60% position will generate big difference that could make the test nonsense. Specially, the position change is happened in the center of curves. Unless your system falls into some very strange behavior.
Weifeng Tang ? I think Median or 90% are both OK to rep your test if your tested application is error free. Both of them get rid of the spikes and better than Average.
However, the strange spikes ( not one) in the middle of the execution seems problematic. It might be some resource competition at that time or pool expansion that incurred this point. Though performance curves are not expected to be normal, yet I always try to find a stable curve. I'll doubt myself if need present this result to my client. Anyway I have no knowledge of your circumstance, you may have your own limitations or assumptions to do so.
Peter Booth ? Can you add some detail to this data? Is the response time curve a scatterplot of every response time with the horizontal axis being the number of datapoints? How long was your test run? Did it show a spike of 3.5seconds during the test?
What are the three columns on the percentile table showing? Is this milliseconds or seconds? Are these percentiles with and without outliers? Is it the result of only a single test run?
Peter Booth ? Feng,
Some comments on the data:
1. Obviously the large spike that appears in one of the test runs is an issue. Does it represent usual behavior (say a full GC cycle) or a one-off issue?
2. The individual data points are in the tens of milliseconds. What is the request rate of the test workload?
3. Are these dynamic web requests?
4. Are you familiar with hypothesis testing, significance, and the statistical power of test designs? You can get more information from 54x 10 minute tests than 3x 3 hr tests, and will be able to see whether your results are consistent.
Peter Booth ? Right now you have a few long-lived test runs at a modest request rate (33 req/sec), and they show that most requests are served within 30 to 40 ms. If we ignore the spike and use the median response time of 33ms as an estimate of response time, then Little's Law implies there will be on average 33*(2000/60) / 1000 = 1.11 requests in the system at any time. Thats a pretty small number.
If it were me, I'd want to begin measuring performance under a trivially small workload (1 or 2 requests per second) . First thing is to look at a scatter plot of response times - are there any obvious trends? banding? cycles? I would want to estimate the EJB service time. Does your DB also expose transaction response times / AWR reports or similar? If not, I'd want to use a tool like NewRelic to capture and cross reference the DB performance against EJB performance.
I'd want to run a large number of short test runs to see if the performance numbers are consistent from run to run. I'd probably use a shell script to run tests using wrk or httperf and, after measuring the best-case EJB performance under a light load, would go onto measure the performance as workload increases, using autoperf or similar. I'd be measuring median, 90th % and 10% values. For this my goal would be to quantify scalability using the approach described http://www.perfdynamics.com/Manifesto/USLscalability.html or http://www.percona.com/files/white-papers/forecasting-mysql-scalability.pdf
Subscribe to:
Posts (Atom)